EDA 3번째 시간
이번 목표는 아래 3가지이다.
- 선수 특성 사이의 상관성을 파악해보기
- 매치 데이터에 팀 특성 데이터를 통합하기
- 홈, 어웨이 골 정보를 활용하여 승/무/패 범주로 변환하기
선수 특성 사이의 상관성 파악하기
상관성 파악을 위해 heatmap으로 corr() 을 그려보자
fig = plt.figure(figsize = (5, 15))
sns.heatmap(df_player_att.drop(['id', 'player_fifa_api_id', 'player_api_id'], axis = 1).corr()[['overall_rating']], annot=True)이전에 진행했던 heatmap 코드들과 비교했을 때 조금 더 복잡해보일 수 있지만,
의미는 크게 달라진게 없다.
우선 상관성 파악과 무관한 컬럼들을 drop하였고 (id 관련 변수들)
주요 변수인 overall_rating과 다른 컬럼들 간의 상관성을 보기 위한 코드이다.
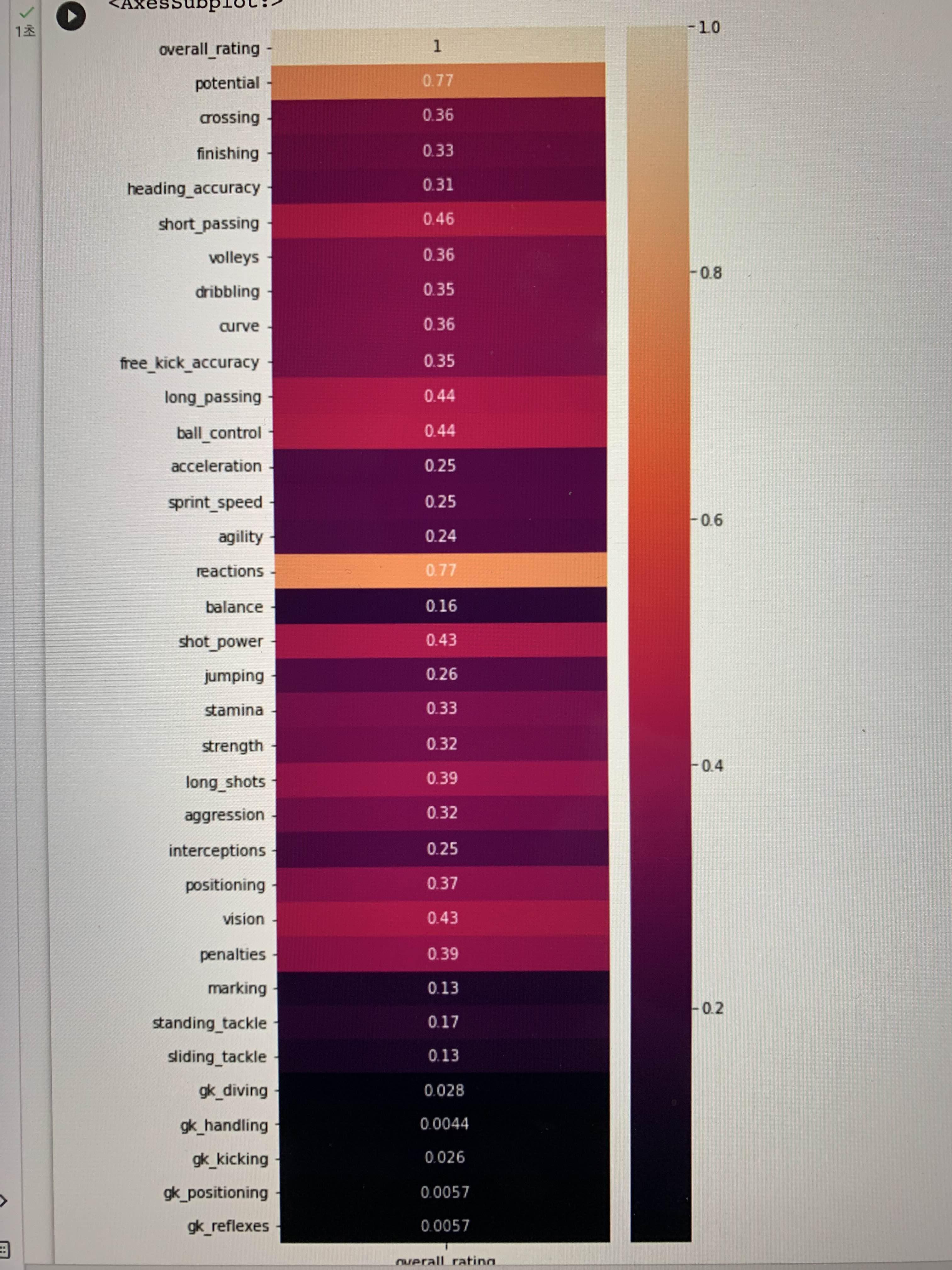
결과로 보면 overall_rating과 상관성이 높은 변수들은 포텐셜, 리액션, 숏패스, 롱패스, 볼 컨트롤, 슛파워, 비전 순으로 확인된다.
매치 데이터에 팀 특성 데이터를 통합하기
모델링 분석을 위한 데이터 세팅에 있어 필요한 과정 중 하나이다.
dt_team_att 내 데이터 분포를 보았을 때 buildUpPlayDribbling에 null이 많아 해당 컬럼은 drop 처리를 우선 진행했다.
이후 해당 team_api_id 기준으로 대표되는 정보로 aggregate 과정이 필요한데,
이 때 수치형과 범주형 데이터에 대한 처리 기준을 고민해야 된다. (아래 코드 참고)
## 범주형 데이터의 aggregate를 위한 함수 정의 >> 최빈값을 대표값으로 보기 위함이다
def most(x):
return x.value_counts().index[0]
# team_map에서 각 팀별 aggregate된 값들을 정의한다.
## 수치형의 경우 평균값으로
## 범주형의 경우 위 most 함수 정의를 활용하여 최빈값으로 표현한다
team_map = df_team_att.groupby('team_api_id').aggregate(
{
'buildUpPlaySpeed': 'mean',
'buildUpPlaySpeedClass': most,
'buildUpPlayDribblingClass': most,
'buildUpPlayPassing': 'mean',
'buildUpPlayPassingClass': most,
'buildUpPlayPositioningClass': most,
'chanceCreationPassing': 'mean',
'chanceCreationPassingClass': most,
'chanceCreationCrossing': 'mean',
'chanceCreationCrossingClass': most,
'chanceCreationShooting': 'mean',
'chanceCreationShootingClass': most,
'chanceCreationPositioningClass': most,
'defencePressure': 'mean',
'defencePressureClass': most,
'defenceAggression': 'mean',
'defenceAggressionClass': most,
'defenceTeamWidth': 'mean',
'defenceTeamWidthClass': most,
'defenceDefenderLineClass': most
}
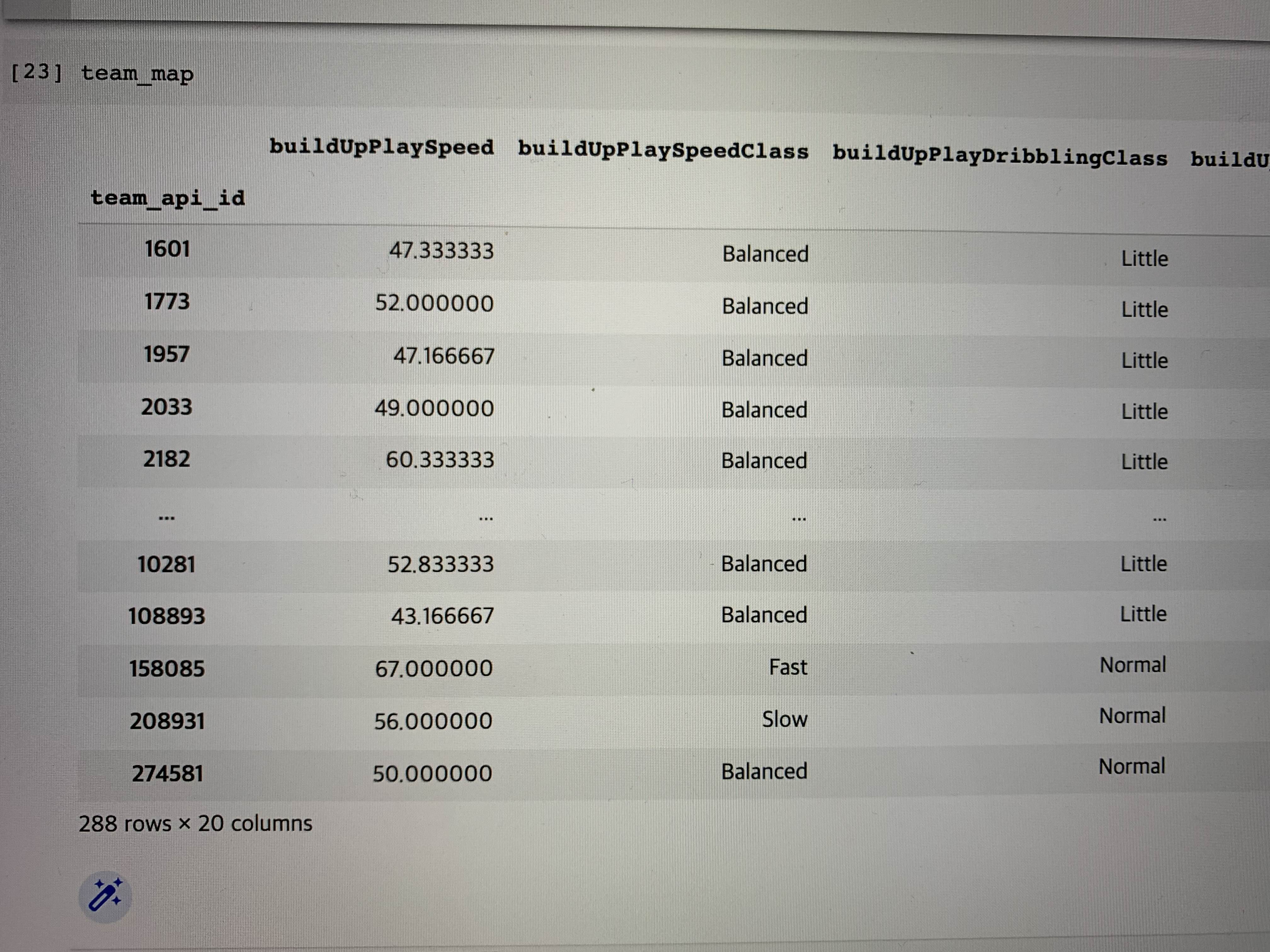
)위 과정을 통해 정리된 team_map 데이터의 형태는 아래와 같다.
이렇게 각 팀별 특성을 정리한 뒤에 df_match 데이터의 득점 변수('home_team_goal', 'away_team_goal')을 덧붙여서
두 데이터를 통합하는 절차를 진행한다.
## df_match에서 활용한 변수만 df 데이터프레임에 넣어두기
df = df_match[['home_team_goal', 'away_team_goal']].copy()
## for 문을 활용하여 team_map에 해당되는 변수들을 각각 home과 away가 붙은 변수명으로 정리하는데
## 이 때 해당되는 columns들은 team_map에 있는 변수 전체가 되도록 정의한다.
for team in ['home_', 'away_']:
team_map.index.name = team + 'team_api_id'
for col in team_map.columns:
df[team + col] = df_match[team_map.index.name].map(team_map[col])
## 이렇게 정리된 df 데이터프레임에서 NaN 값이 있다면, drop한다
df.dropna(inplace = True)이렇게 최종적으로 통합된 df 데이터프레임의 형태이다.

홈, 어웨이 골 정보를 활용하여 승/무/패 범주 변환
# 홈과 어웨이의 골 수를 범주형 데이터로 변환하기 (0: 홈팀 승, 1: 무승부, 2: 어웨이팀 승)
df['matchResult'] = df[['home_team_goal', 'away_team_goal']].aggregate(lambda x: 0 if x[0] > x[1] else 1 if x[0] == x[1] else 2, axis = 1)코드상으로는 1줄짜리이지만,
이 안에 고민해야되는 요소들은 간단치 않다.
- 우선 df 데이터프레임 내 결과 변수 matchResult를 추가하도록 하자
- 추가하는 기준은 home_team_goal과 away_team_goal 변수를 aggregate한 기준이다.
- 기준에 대한 상세 조건은
- 홈 골 > 어웨이 골 이면 0 (홈팀 승리)
- 홈 골 = 어웨이 골 이면 1 (무승부)
- 위 2가지가 모두 아니라면(즉, 홈 골 < 어웨이 골) 2 (어웨이팀 승리)
의 구조가 된다.
이렇게 matchResult 컬럼으로 승/무/패 표현이 가능해졌으니,
home_team_goal과 away_team_goal은 drop 하도록 하자
df.drop(['home_team_goal', 'away_team_goal'], axis = 1, inplace = True)
강의 기준으로만 따라가는데도 쉽지않다.
험난한 EDA 과정이 강의상으로는 이렇게 마무리가 되었는데
체감으로는 아직 만족스럽지 않은 느낌적인 느낌이다.
오늘도 다시 한번 복습을 해야겠다...
http://bit.ly/3Y34pE0
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'Analytics > Study' 카테고리의 다른 글
| 실전#4 오늘 밤 유럽 축구, 어디가 이길까(6) (0) | 2023.03.13 |
|---|---|
| 실전#4 오늘 밤 유럽 축구, 어디가 이길까(5) (0) | 2023.03.12 |
| 실전#4 오늘 밤 유럽 축구, 어디가 이길까(3) (0) | 2023.03.10 |
| 실전#4 오늘 밤 유럽 축구, 어디가 이길까(2) (0) | 2023.03.09 |
| 실전#4 오늘 밤 유럽 축구, 어디가 이길까(1) (0) | 2023.03.08 |



