실전에 앞서 3번째Intro
이미 익숙한 내용들도 있기는 하지만,
기회가 기회인만큼 이참에 정리를 한번 하고 넘어가는게 좋을 것 같아
빠르게 정리를 해보았다.
시작에 앞서 인증샷 짠!

데이터 분석의 일반적인 순서
1. Data Processing
2. Exploratory Data Analysis(EDA)
3. Feature Engineering
4. Machine Learning
Data Processing
- 데이터 가져오는 과정
- Kaggle, CSV, SQL 등 다양한 방법을 통해 데이터 확보
- Pandas를 통해 수집한 데이터를 확인하는 과정까지 포함
- 마트성 데이터가 있다면 이후 과정이 수월할 수 있겠지만, Raw 데이터를 가져오는 상황이라면 이후 EDA, Feature Engineering 과정을 반복하면서 최종 분석용 데이터가 세팅될 수 있다.
Exploratory Data Analysis
- 데이터 EDA 단계
- 데이터들의 분포와 통계치 등을 확인하는 단계
- 언제나 중요하게 강조했던 내용은 EDA에서 데이터의 분포를 살펴봐야 한다!
- 특정 구간에 몰려있진 않은지, 결측치가 많진 않은지, 랜덤 분포는 아닌지, 연속형이지만 binary로 해석할 수 있진 않은지 등등
- 훓어보는 단계를 통해 변수들간의 특징을 파악하고, 필요하다면 변수를 제외 or 변환할 수 있도록 아이디어를 모은다.
- 이 과정에서 시간을 많이 보내게 되는데, 적당한 작업 일정을 정해 어느정도 충족했다면 다음 단계로 넘어갈 필요가 있다.
- 그렇지 않다면, 시간 소요가 길고 본래의 목적을 놓칠 가능성이 있다.
Feature Engineering
- 데이터 전처리 단계
- 데이터 분석을 위한 사전 작업 단계
- 데이터의 결측치, 이상치, 중복값 등을 어떻게 처리할 지 정하고 이 과정을 통해 필요한 변수를 추출하는 작업
- 최종적으로 분석용 마트 데이터셋이 완성
Machine Learing
- 모델링 단계
- 분석 목적에 맞는 모델을 선택하고 적용
- 테스트 셋과 트레인 셋을 구분하여 적합한 모델 선정을 위한 비교 및 발굴 작업
위 내용들에서 개인적으로 추가하고 싶은 내용
0. 목표 수립: 분석 목적을 명확하게 설정해야 되는 것 또한 매우 중요한 것 같다. 문제 정의와 가설 수립, 목적에 맞는 데이터 수립 등의 과정이 여기에 해당
5. 결과 해석: 모델링 단계 이후 해당 모델링에 대한 해석 또한 중요하다. 이를 토대로 의사결정을 내려야 하는데 결과 해석 과정이 없으면 원활한 의사결정 또한 어려울 수 있다.
2~5. 시각화: 전반적인 과정에서 필요한 과정 중 하나는 시각화인 것 같다. 진행한 내용과 결과를 쉽게 파악하고 설명할 수 있도록 시각화 작업을 꼭 포함해야 된다. 이 과정이 잘 진행된다면, 5번의 결과 해석도 쉽고 명확하게 진행될 것으로 기대된다.
* 참고 - CRISP-DM (Cross Industry Standard Process for Data Mining) 모델
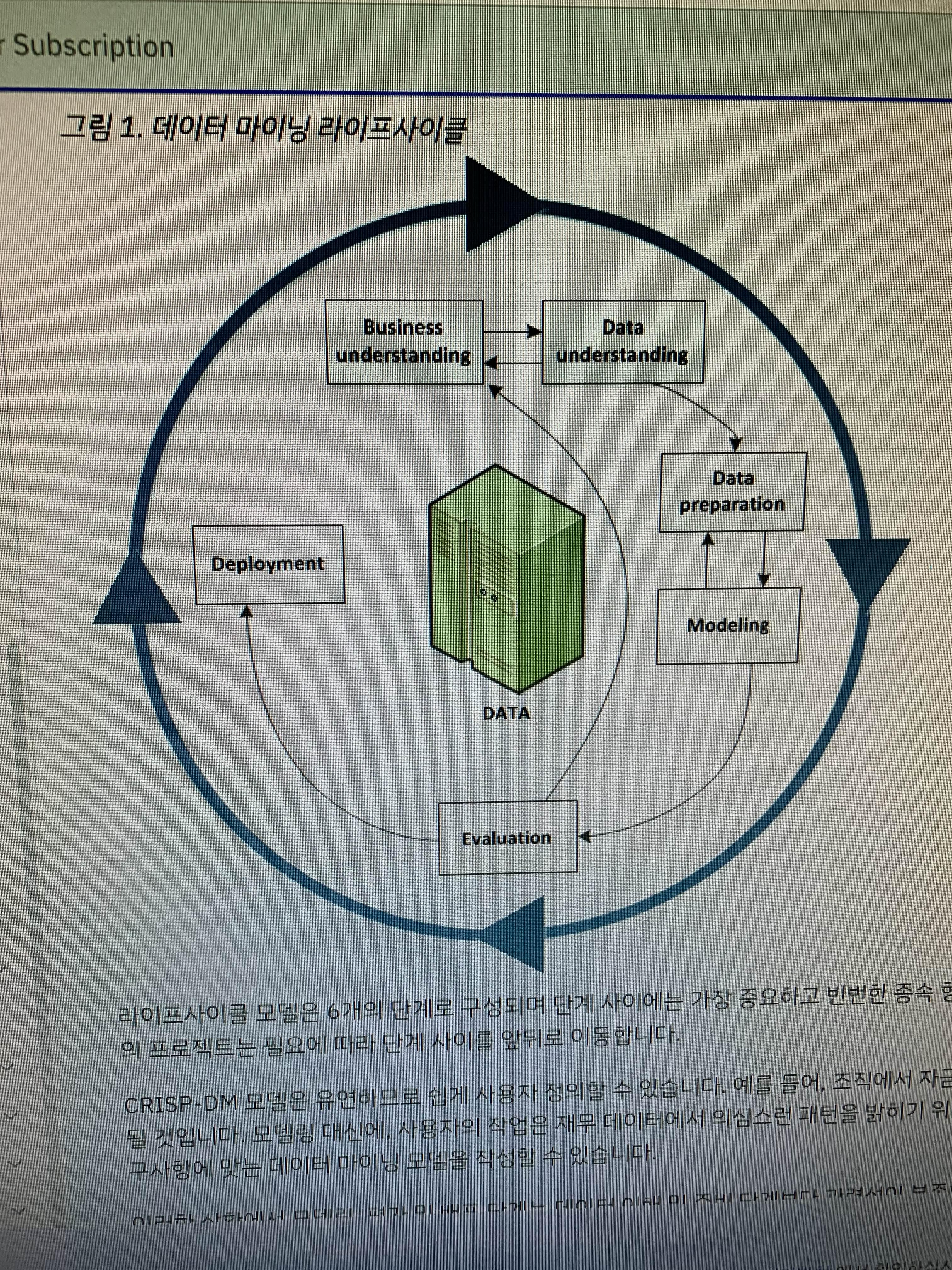
http://bit.ly/3Y34pE0
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'Analytics > Study' 카테고리의 다른 글
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(3) (0) | 2023.02.25 |
|---|---|
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(2) (0) | 2023.02.24 |
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(1) (0) | 2023.02.23 |
| 기본 라이브러리 정리_2 (0) | 2023.02.21 |
| 파이썬머신러닝300제 강의 시작! (기본 라이브러리 정리_1) (0) | 2023.02.20 |



