데이터를 확보했으니, 다음 단계는 EDA 과정이다.
우선 데이터 확보 후 기본적으로 진행하는 절차들은 아래 3가지 코드가 될 것 같다
# 데이터 기본 확인
df.head()
# 각 컬럼별 null 존재, 타입, 전체 count
df.info()
# 각 컬럼별 기초 통계정보 (count, mean, std, min, 25%, 50%, 75%, max)
df.describe()1) df.head() 를 통해
: 기본적인 데이터의 형태를 알 수 있다. 특정 컬럼에 어떤 값들이 들어와있는지 등
2) df.info() 를 통해
: 컬럼별 정보를 확인하면서 null(결측치)가 존재하지는 않는지, 컬럼을 정의한 Type은 무엇인지 등을 알 수 있다.
3) df.describe() 를 통해
: 컬럼별 기본적인 통계 정보를 확인. 양 극단(min, max)으로 갈수록 데이터 이상치로 보이는 컬럼은 없는지, 각 컬럼들의 전체적인 수준은 어떠한지 등
이후 시각화를 통한 컬럼별 정보를 추가적으로 참고한다
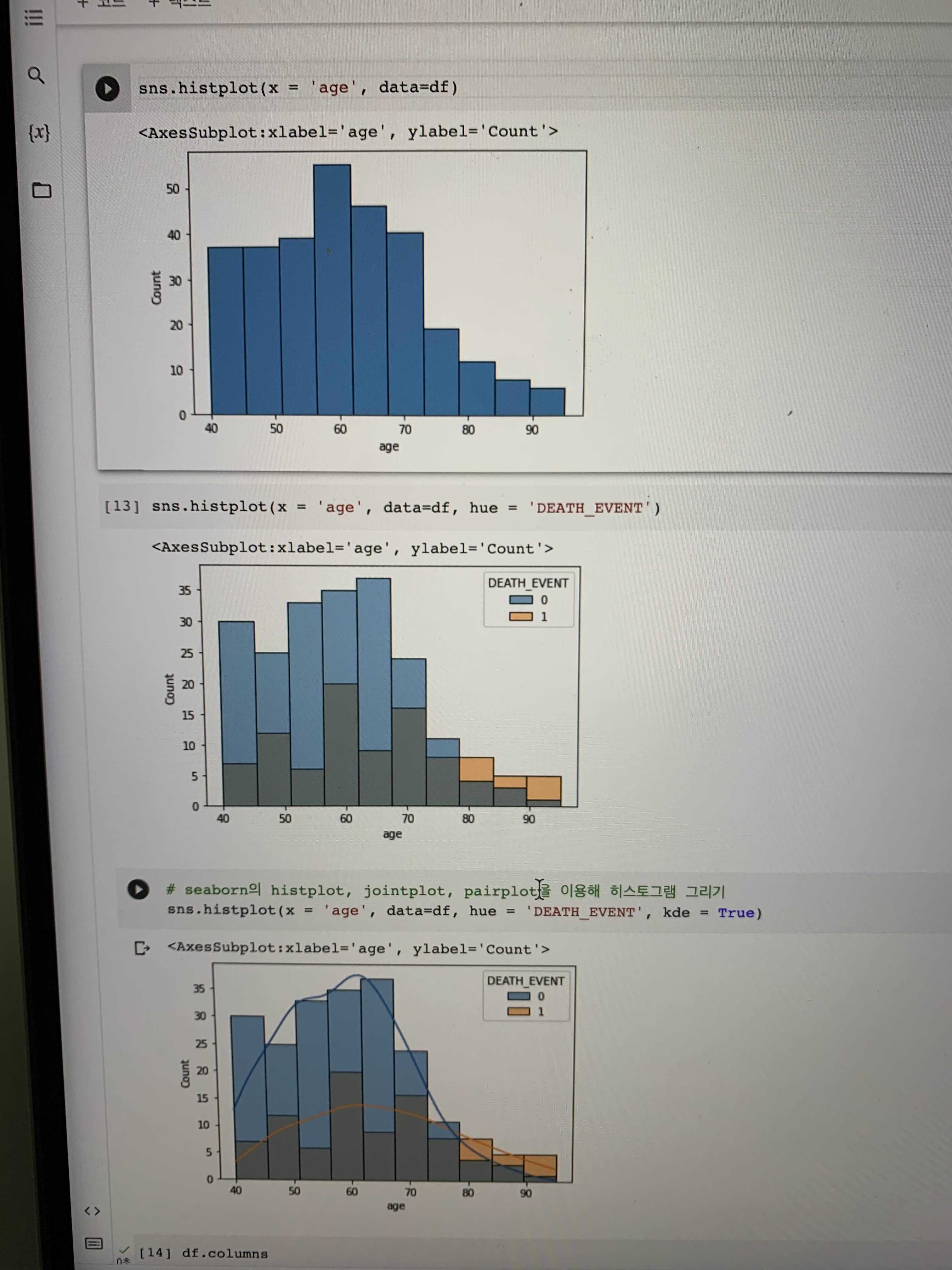
1) 히스토그램
# 히스토그램_기본
sns.histplot(x = '변수', data = df)
# 히스토그램_파라미터들
data: 데이터셋
x: 열에 해당하는 데이터
hue: 범주형 변수에 따른 분리!
multiple: 분리된 히스토그램의 중첩 여부
bins: 히스토그램 막대 개수
binwidth: 막대 폭
binrange: 범위
cumulative: 누적 히스토그램 여부
stat: y축에 표시할 값 (count, density, probability)
kde: 밀도 그래프 여부
kde_kws: 밀도 그래프에 대한 추가 파라미터
color: 색상
alpha: 투명도
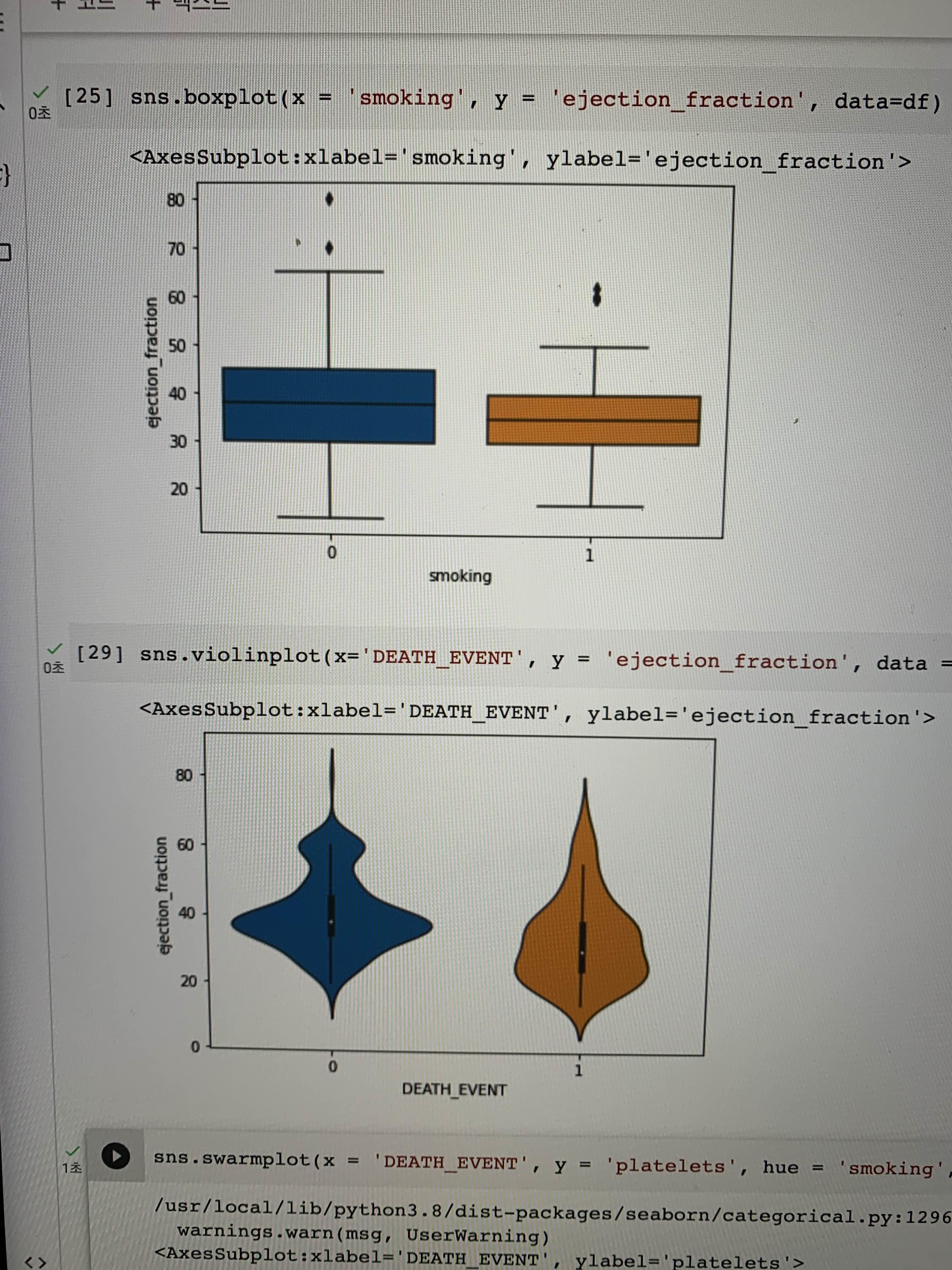
2) boxplot
# boxplot 기본
sns.boxplt(x = '컬럼명', y = '컬럼명', data = df )
# 각 파라미터별
x, y: 각각 x축, y축에 해당하는 변수를 지정합니다.
data: 사용할 데이터를 지정합니다.
hue: 범주형 변수를 지정하여 그룹별 비교를 가능하게 합니다.
palette: 그래프에서 사용할 색상 팔레트를 지정합니다.
order, hue_order: 각각 x, hue 축의 순서를 지정합니다.
showfliers: 이상치를 그래프에 표시할지 여부를 지정합니다.
width: 박스의 너비를 지정합니다.
3) jointplot
# jointplot 기본
sns.jointplot(x = '컬럼명', y = '컬럼명', data = df)
# 각 파라미터들
x, y: 시각화하려는 두 변수
data: 시각화할 데이터셋
kind: 플롯 유형. 'scatter', 'reg', 'hex', 'kde', 'resid' 등이 있습니다.
color: 산점도의 색상
height: 플롯의 높이
ratio: x-y 비율
space: 서브 플롯 간의 간격
4) violinplot
: 히스토그램과 boxplot을 한번에 볼 수 있는 시각화 방법
같이 볼 수 있다는 것은 장점인데... 실제로는 히스토그램 따로 boxplot 따로 보는게 더 나은것 같다(개인 의견)
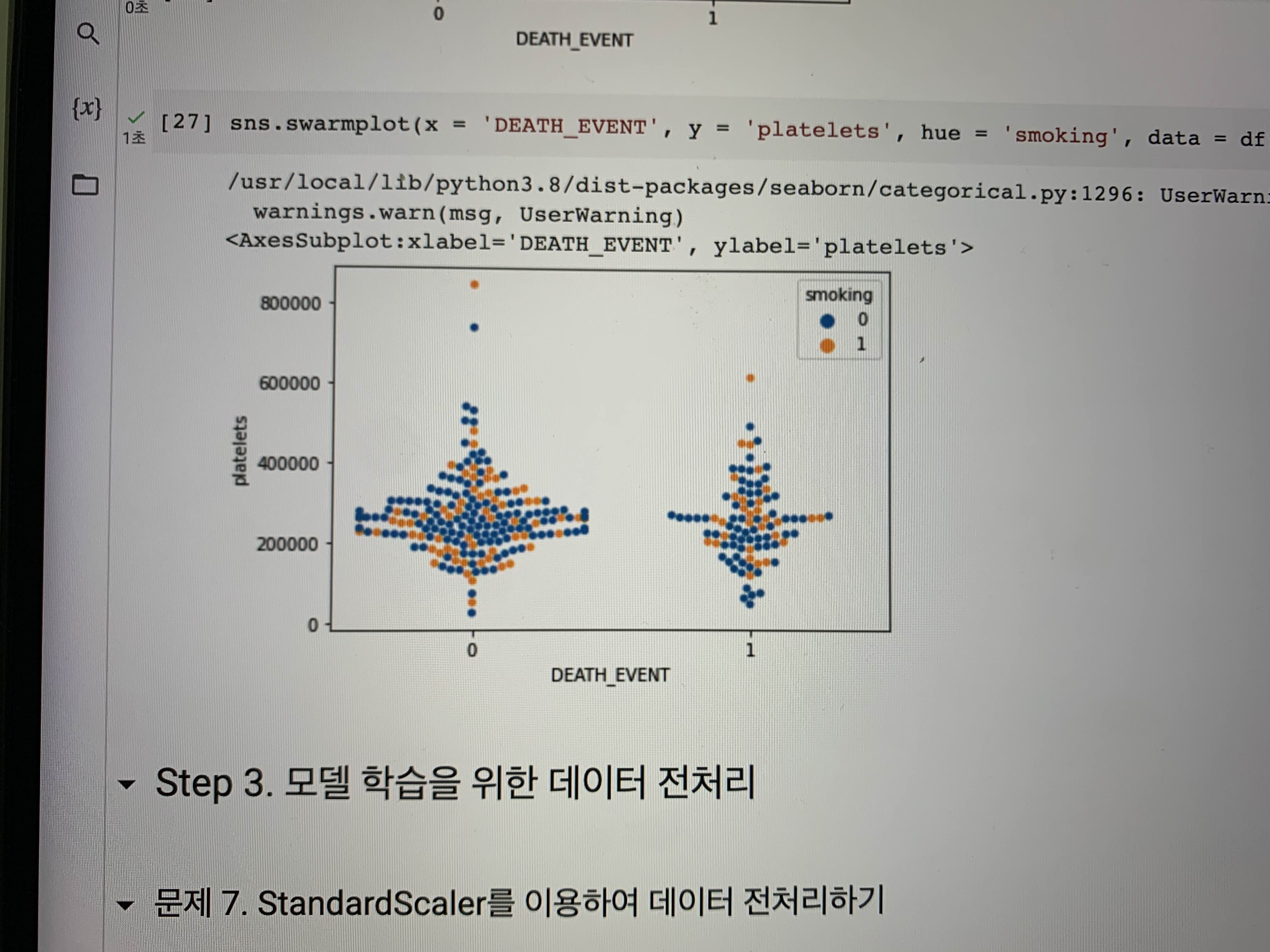
5) swarmplot
: 스캐터와 히스토그램을 조합한 시각화 방법
범주형 변수별 구분을 분포 관점에서 보게 될 때 유용할 수 있다
http://bit.ly/3Y34pE0
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'Analytics > Study' 카테고리의 다른 글
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(4) (0) | 2023.02.26 |
|---|---|
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(3) (0) | 2023.02.25 |
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(1) (0) | 2023.02.23 |
| 데이터 분석에 대한 일반적인 정리 (0) | 2023.02.22 |
| 기본 라이브러리 정리_2 (0) | 2023.02.21 |



