Classification 모델 학습하기
강의에서는 2가지 모델을 활용하였다.
우선 첫번째로 사용한 Logistic Regression부터 정리해보자
from sklearn.linear_model import LogisticRegression
# LogisticRegression 모델 생성/학습
model_lr = LogisticRegression()
model_lr.fit(X_train, y_train)
# 모델 평가
from sklearn.metrics import classification_report
# Predict를 수행하고 classification_report() 결과 출력하기
pred = model_lr.predict(X_test)
print(classification_report(y_test, pred))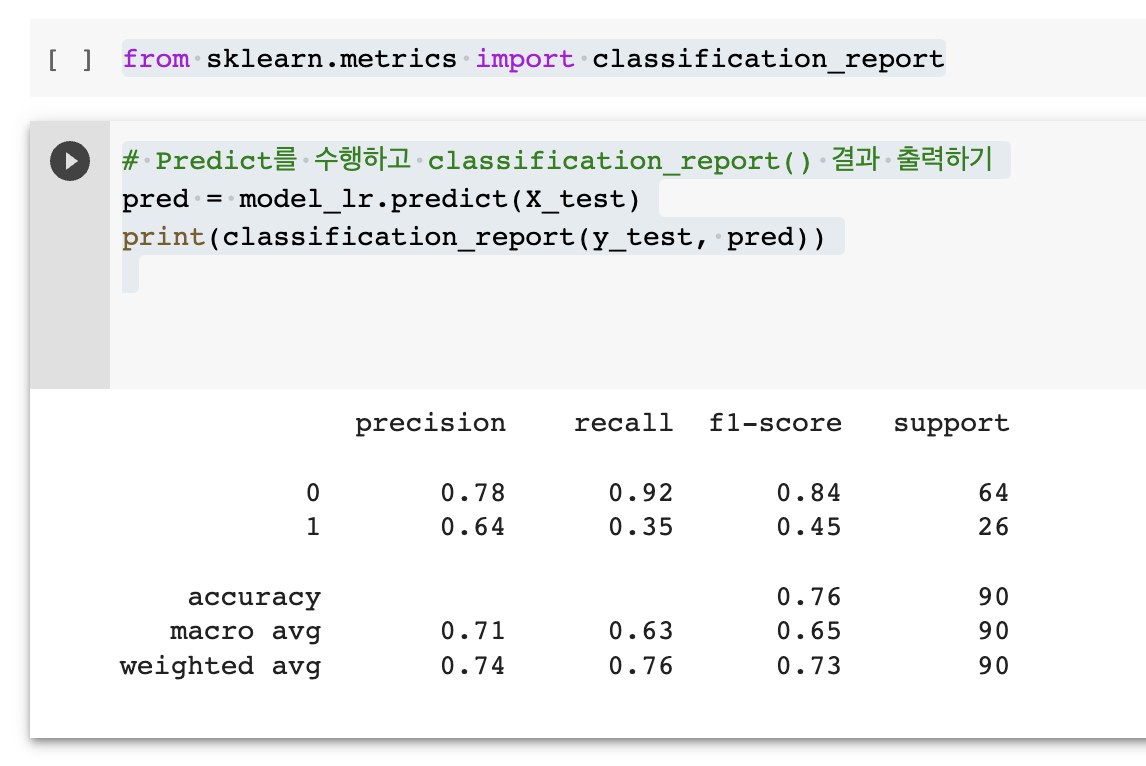
로지스틱 회귀는 이름대로 회귀로서 데이터를 분석하고 예측하는 알고리즘이다.
일반적인 회귀와 차이라면 로지스틱은 이진 분류(binary classification)에서 활용되는 것으로
입력된 변수(feature)와 출력 변수(target) 사이의 관계를 찾아내어 새로운 입력값에 대한 결과값을 예측하는 목적이다.
떄문에 로지스틱의 target은 0과 1 사이의 값으로 제한되며,
이를 위해 시그모이드 함수를 하용하고, 로지스틱 함수라고 불린다.
시그모이드 함수에 관하여

로지스틱 회귀는 분류 문제에 있어 간단하고 빠르게 결과 예측이 가능하며, 해석도 이해하기 쉬운 장점이 있는 반면
데이터가 복잡할수록 제대로된 분석 결과를 얻기에 한계가 있다는 단점도 있다. (특히 변수들의 분포가 모두 정규분포가 아니라면, 각각의 변수를 전처리하는데 많은 시간 소요가 필요하다)
두번째로 활용한 모델은 xgboost 이다.
from xgboost import XGBClassifier
# XGBClassifier 모델 생성/학습
model_xgb = XGBClassifier()
model_xgb.fit(X_train, y_train)
# Predict를 수행하고 classification_report() 결과 출력하기
pred = model_xgb.predict(X_test)
print(classification_report(y_test, pred))
xgboost는 gradient boosting 알고리즘을 기반으로 한 머신러닝 라이브러리이다.
로지스틱 회귀가 단일 분석의 결과라면, xgboost는 여러개의 의사결정 트리를 학습시켜 각 트리의 오차를 보완하며 예측 성능을 개선해준다.
당연히 모델의 성능, 안정성에서 좋은 편이고, 강의에서 추가 설명해준 것처럼 kaggle에서도 고득점에 인기 높은 라이브러리 중 하나라고 한다.
특히 대용량의 데이터셋일수록 장점이 발휘되고, 시간 소요에서도 효율적인 편이다.
추가로 xgboost 모델 결과를 활용하여 각 변수(feature)별 모델과의 중요도를 알 수 있다.
# XGBClassifier 모델의 feature_importances_를 이용하여 중요도 plot
# plt.plot(model_xgb.feature_importances_)
plt.bar(X.columns, model_xgb.feature_importances_)
plt.xticks(rotation = 90)
plt.show()
모델 학습 결과 심화 분석하기
위 예시처럼 모델을 여러개 시도해보면서 가장 적절한 모델을 선택하는 경우가 있는데
이 때 추가로 분석에 도움이 되는 과정이 아래의 과정들이다.
precision-Recall 커브 확인
from sklearn.metrics import plot_precision_recall_curve
# 두 모델의 Precision-Recall 커브를 한번에 그리기
fig = plt.figure()
ax = fig.gca()
plot_precision_recall_curve(model_lr, X_test, y_test, ax = ax)
plot_precision_recall_curve(model_xgb, X_test, y_test, ax = ax)이전에도 정리했던 Confusion matrix를 시각화로 확인하는 방법이다.
아래의 그래프를 통해 threshold에 따라 모델이 True, False로 예측하는 precision과 recall의 변화가 어떻게 변화하는지 알 수 있는데
threshold를 높일수록 precision은 높아지고, recall은 낮아진다. (반대의 경우도 당연히 반대)
이 때 모델 성능 평가의 지표로 사용되는 것이 AP인데, AP란 Average Precision으로 1에 가까울수록 좋은 모델로 볼 수 있다.

ROC 커브 확인하기
from sklearn.metrics import plot_roc_curve
# 두 모델의 ROC 커브를 한번에 그리기
fig = plt.figure()
ax = fig.gca()
plot_roc_curve(model_lr, X_test, y_test, ax = ax)
plot_roc_curve(model_xgb, X_test, y_test, ax = ax)ROC 커브는 Receiver Operating Characteristic의 약어로 True Positive Rate와 False Positive Rate 사이의 관계를 나타내는 곡선이다. 이 때 AUC(Area Under the Curve) 값을 통해 모델 성능을 평가할 수 있는데, 1에 가까울수록 모델의 성능이 높다고 평가할 수 있다.

위 과정들을 종합적으로 확인했을 때
xgboost의 성능이 더 좋다고 볼 수 있는데
단순 결과로만 평가하는 방법보다는
각 모델을 통해 해석된 결과와 사용된 데이터의 상황을 모두 고려하여
본래 목적에 더 적합한 내용으로 활용하는 것이 가장 중요할 것 같다.
실전 첫번째 심부전증 예방 관련 분석은 여기서 끝!!
http://bit.ly/3Y34pE0
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'Analytics > Study' 카테고리의 다른 글
| 실전#2 데이터로 살펴보는 우리 아이 학습 성공/실패 요소(1) (0) | 2023.02.28 |
|---|---|
| 실전#1 에필로그?! (0) | 2023.02.27 |
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(3) (0) | 2023.02.25 |
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(2) (0) | 2023.02.24 |
| 실전#1. 데이터 분석으로 심부전증을 예방할 수 있을까(1) (0) | 2023.02.23 |



