드디어 마지막 강의!
모델 학습 및 결과를 해석해보자
이전까지는 로지스틱회귀모델과 XGBoost 모델만을 다루었는데
이번 강의에서는 lightgbm 패키지에 있는 LGBMRegressor을 활용하였다.
본 내용에 들어가기 전에 LGBMRegressor에 대해 조금 더 알아보도록 하자
LGBMRegressor는 LightGBM 라이브러리에서 제공하는 회귀 분석용 클래스로, Gradient Boosting Decision Tree 알고리즘을 기반으로 한 트리 기반의 앙상블 학습 방법 중 하나이다.
LGBMRegressor는 데이터셋을 학습시켜 트리 기반 모델을 생성하고, 예측값을 출력하는데 이 때, 예측값은 입력된 데이터의 속성(feature)들을 기반으로 하여 계산된다.
LGBMRegressor 클래스에서 제공되는 하이퍼파라미터들 중 몇 가지 중요한 항목들만 정리해보자
- learning_rate: 경사하강법에서 이동 거리를 조절하는 파라미터로, 값이 작을수록 안정적인 학습이 가능하지만 더 많은 시간이 소요될 수 있다
- n_estimators: 생성할 트리 모델의 개수. 이 값을 높일수록 모델의 복잡도가 증가하므로 과적합(overfitting)의 가능성이 높아진다.
- max_depth: 생성될 트리의 최대 깊이를 지정한다. 이 값을 높일수록 모델의 복잡도가 증가하므로 과적합의 가능성이 높아진다.
- min_child_samples: 하나의 노드에서 분할될 최소한의 데이터 샘플 개수를 지정한다. 이 값을 높일수록 모델이 덜 복잡해지고 과적합의 가능성이 줄어든다.
- reg_alpha: L1 정규화(regularization) 강도를 지정한다. 이 값을 높일수록 모델이 덜 복잡해지고 과적합의 가능성이 줄어든다.
LGBMRegressor 클래스를 사용하여 트리 기반 모델을 생성하고 학습시키는 과정은 일반적으로 다른 트리 기반 앙상블 학습 방법과 비슷하다. 하지만 LightGBM은 다양한 성능 최적화 기법을 사용하여 대규모 데이터셋에서 빠르게 학습할 수 있다는 장점이 있어서 특히 대용량 데이터셋에서 많이 활용되는 알고리즘 중 하나이다.
추가로 하이퍼파라미터 설정 자체에 대해서도 최적화를 계산하는 방법도 함께 있어 다양한 모델 학습을 시도하는 과정에서 사용자의 판단에 의한 설정과 자동으로 최적화 계산을 통해 산출된 설정을 비교하는 것도 모델 성능 향상에 도움이 될 수 있다.
실제 데이터에 적용되는 코드는 아래와 같다
from lightgbm import LGBMRegressor
# LGBMRegressor 모델 생성/학습. Feature에 PCA 적용하기
model_reg = LGBMRegressor()
# model_reg.fit(pca.transform(X_train), y_train)
model_reg.fit(X_train, y_train)
# 모델 정확도 출력하기
from sklearn.metrics import mean_absolute_error, mean_squared_error
from sklearn.metrics import classification_report
from math import sqrt
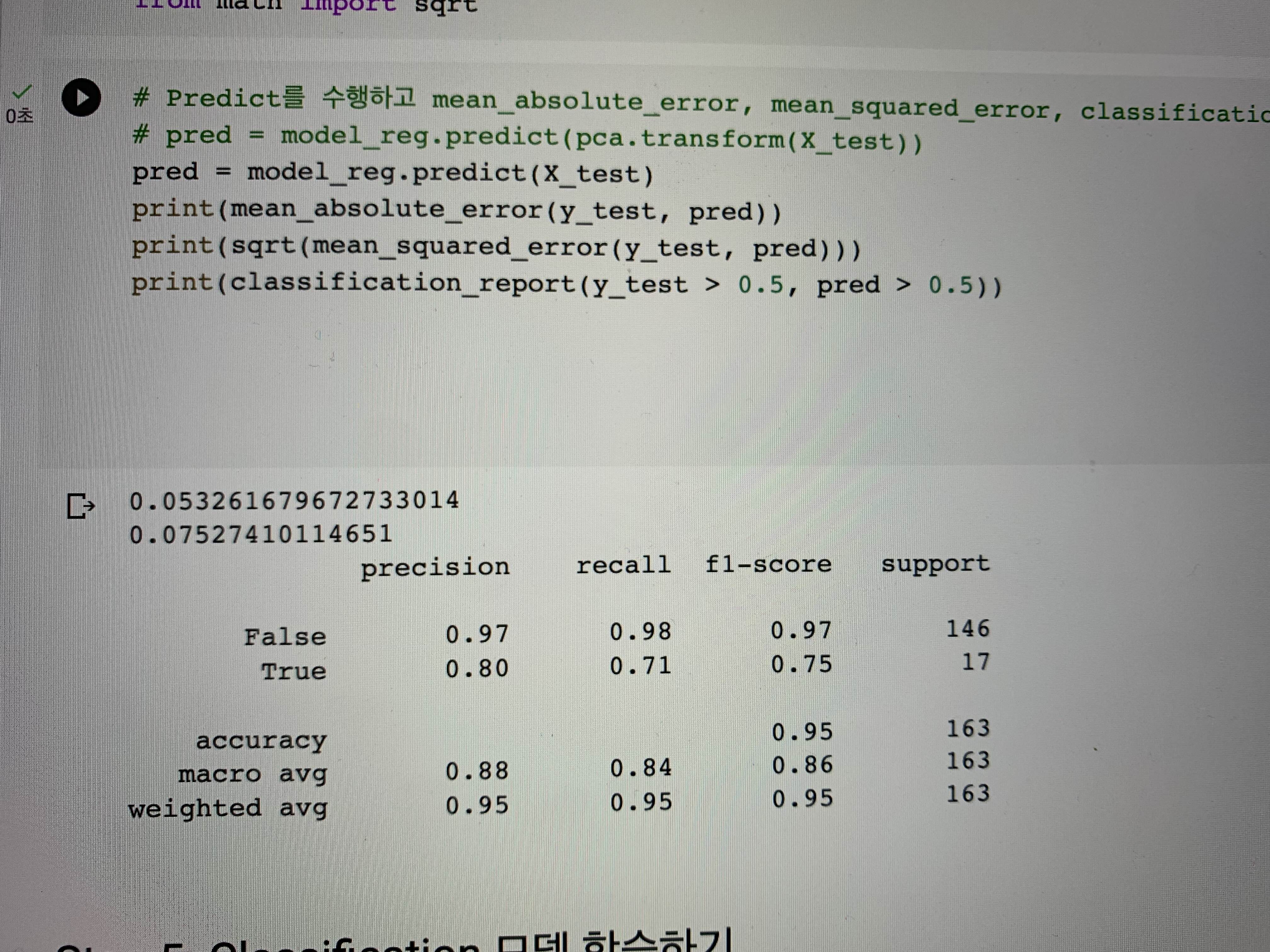
# Predict를 수행하고 mean_absolute_error, mean_squared_error, classification_report 결과 출력하기
# pred = model_reg.predict(pca.transform(X_test))
pred = model_reg.predict(X_test)
print(mean_absolute_error(y_test, pred))
print(sqrt(mean_squared_error(y_test, pred)))
print(classification_report(y_test > 0.5, pred > 0.5))내용 중간 중간 주석 처리가 된 부분이 있는데
이전에 다루었던 pca를 적용한 기법과 전체 데이터에 대해 학습한 모델을 비교하기 위해 2가지 버전이 존재하고 있다.
결론부터 말하자면 pca를 적용한 모델보다 적용하지 않은 모델에서의 성능이 더 좋게 나와
pca 관련 코드 부분만 주석처리를 하였다.
그리고 다음은 XGBoost 모델이다.
from xgboost import XGBClassifier
# XGBClassifier 모델 생성/학습
model_cls = XGBClassifier()
model_cls.fit(X_train, y_train > 0.5)
# XGBClassifier 모델의 feature_importances_ 속성 시각화
plt.bar(X.columns, model_cls.feature_importances_)
plt.xticks(rotation = 90)
plt.show()
# Predict를 수행하고 classification_report() 결과 출력하기
pred = model_cls.predict(X_test)
print(classification_report(y_test > 0.5, pred))
이전과 조금 다른 부분이 있다면, model fit 과정에서 y_train에 > 0.5 조건이 추가된 내용이다.
이는 y_train에 해당되는 값이 모두 실수형이기에 0.5를 기준으로 초과시 1, 이하이면 0으로 binary처리를 한 내용이다.
XGBoost 모델 학습의 결과도 굉장히 높게 나왔는데,
feature importance를 시각화로 표현하여 내용을 살펴보면
전체 인구수가 높은 지역에서, 아시안 인종 비율이 높은 지역에서, 백인 인종 비율이 높은 지역에서, PublickWork(공무원?) 비율이 높을수록 높은 영향도를 보이고 있었다.

결과랑 함께 생각해보면 어느정도 수긍이 되는 것도 같다
여기까지가 전체 분류모델 관련 강의의 마지막 장이었다.
이후 다른 모형과 주제들도 계속해서 깨부셔?보자!
http://bit.ly/3Y34pE0
본 포스팅은 패스트캠퍼스 환급 챌린지 참여를 위해 작성되었습니다.
'Analytics > Study' 카테고리의 다른 글
| 실전#5 미국의 대통령은 어떻게 뽑힐까(6) (0) | 2023.03.20 |
|---|---|
| 실전#5 미국의 대통령은 어떻게 뽑힐까(5) (0) | 2023.03.19 |
| 실전#5 미국의 대통령은 어떻게 뽑힐까(4) (0) | 2023.03.18 |
| 실전#5 미국의 대통령은 어떻게 뽑힐까(3) (0) | 2023.03.17 |
| 실전#5 미국의 대통령은 어떻게 뽑힐까(2) (0) | 2023.03.16 |



